Every AI tool you use today sends your data somewhere else. Every prompt you type into ChatGPT or Claude goes to a server in another country. Someone else's infrastructure. Someone else's rules. Someone else decides whether to keep using that data or change the pricing next month. That's about to change.
The shift to local AI
Open source AI models have crossed a line. They're now good enough to run real business tasks. Not toy demos. Actual work. And they run on hardware you can buy and put on your desk.
NVIDIA just released their Nemotron family of models. Open source, top 3 on global benchmarks (Jensen Huang's claim at GTC last week, and the benchmarks back it up). You can download them, install them on your own machine, and run them without ever connecting to the internet.
I tested this on my own server at home. It works. The responses are slower than cloud models (we're talking seconds, not minutes) but the quality is genuinely good. Good enough that I'm already exploring how to use local models for client work where data sensitivity is the priority.
What "local" actually means
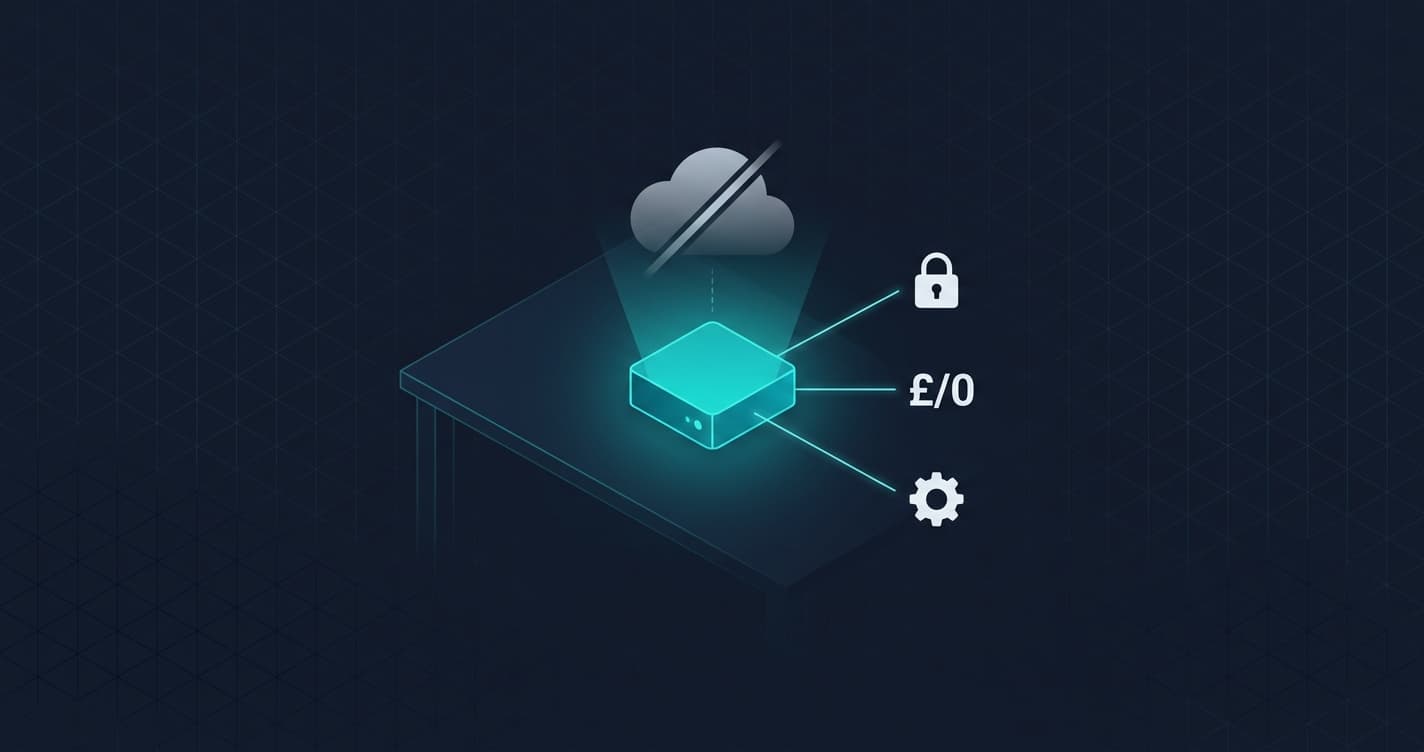
When I say local, I mean the AI model runs on a computer in your office. Or your home. Or a server you control. Your data never leaves the building. No API calls to California. No tokens being sent to a data centre in Dublin. The processing happens right there on your hardware.
Three things change when you run AI locally:
- Privacy becomes absolute. Your prompts, your data, your client information stays on your machine. Not because a company promises not to look at it. Because it physically never leaves. There's nothing to trust because there's nothing to send.
- Cost drops to zero (after hardware). No subscription. No per-token billing. No surprise invoices when your team uses it more than expected. You pay once for the hardware. The AI runs for free after that. The electricity cost is pennies.
- Control is yours completely. Nobody can change the model, make it dumber, ban your account, or raise the price. The model sits on your hardware. It's yours. If NVIDIA releases a better version next month, you upgrade when you want. Not when someone else decides.
The hardware question (it's cheaper than you think)
You don't need a data centre. The Nemotron family comes in three sizes: Nano (for small tasks, runs on a decent laptop), Super (for serious multi-agent work, needs a good GPU), and Ultra (mission-critical reasoning, needs proper hardware like a DGX Spark).
Right now, running the top models locally costs about £3,000 to £4,000 for hardware. That's a DGX Spark or a well-specced Mac Studio. Not cheap, but not insane either. That's a one-time cost that replaces ongoing API bills.
For context: a team of 5 people using Claude API heavily might spend £500 to £1,000 per month on tokens. In 4 to 6 months, the hardware pays for itself. After that it's free.
And the trajectory is clear. Six months from now, hardware that runs frontier-quality models will likely cost £1,000 to £2,000. The price is dropping fast while the models keep getting better.
If you're not ready to invest now, that's fine. But you should understand what's coming so you're not caught off guard when your competitor does it first.
What this means for UK service businesses
I work with accountancy firms, recruitment agencies, law firms. Three things keep coming up in every conversation about AI:
"What happens to our client data?" Local models answer this completely. Your data never leaves your office. Full stop. For accountancy firms handling HMRC submissions, for law firms dealing with case files under SRA rules, for any business under GDPR: local AI is the cleanest possible answer to the data question.
"How much will this cost us ongoing?" With cloud AI, the answer is "it depends and it'll probably go up." With local models, the answer is "nothing after the initial hardware." Budgets love certainty. CFOs love one-time costs.
"What if the provider changes the rules?" Anthropic has been banning people for using their subscriptions with third-party tools. OpenAI changes pricing and rate limits regularly. Google restructures its AI products every few months. When you run models locally, none of that affects you. The model on your hardware doesn't care about anyone's terms of service changes.
The Nemotron coalition
NVIDIA didn't just release models. They built a coalition around them. Cursor (the coding tool millions of developers use), LangChain (the most popular AI agent framework), Mistral, Perplexity, Black Forest Labs. All partnering to make Nemotron the foundation for their products.
This matters because it means these models aren't going to be abandoned next quarter. NVIDIA is investing billions in AI infrastructure and they've publicly committed to continuing development. Nemotron 3 will be followed by Nemotron 4. The ecosystem is growing, not shrinking.
For someone building AI systems for businesses (that's me), this is exciting because it means the local option keeps getting better. Every few months, a new open model drops that's closer to what the cloud providers offer. The gap between "free local model" and "£200/month cloud subscription" is shrinking fast.
How I'm thinking about this for my clients
Right now, I use a hybrid approach. Sensitive tasks (anything touching client data, financial records, personal information) go through enterprise API access with UK data residency. General tasks (research, content drafting, analysis) use cloud models because they're faster and the data isn't sensitive.
What's changing is that the "sensitive tasks" category can now move to local models entirely. An accountancy firm could have a Nemotron model running in their office that processes client documents without any data ever leaving their network. A recruitment agency could run CV screening locally so candidate data stays on premises.
I'm not there yet with client deployments (the alpha tooling needs to mature, and I want it rock solid before putting it in front of clients) but I'm testing it actively on my own server. If you're curious about where this is heading and what it might look like for your business, that's exactly the kind of thing we explore in a free audit.
The practical timeline
| Timeframe | What to expect |
|---|---|
| Right now (March 2026) | Local models work well for developers and technical users. Setup requires Docker, some config, and patience. Quality is genuinely good but the tooling is rough. Good for experimentation, not production client work. |
| 6 months from now | Hardware costs drop to £1,000 to £2,000 for frontier-quality models. Setup gets simpler. Expect one-click installs your IT person or AI consultant can set up in a day. |
| 12 months from now | Running AI locally will be as normal as running a database locally. The question won't be "should we?" but "why are we still paying for cloud AI for tasks that never need to leave our office?" |
The businesses that start understanding this now will be ready when it becomes mainstream. The ones who wait will be paying premium cloud prices while their competitors run the same quality AI for free on their own hardware.
Bottom line
The cloud AI model (send your data somewhere, pay per use, hope they don't change the rules) worked when there was no alternative. Now there is one. Open source models that run on your own hardware, cost nothing after setup, and give you complete control over your data.
I've shipped two apps to the App Store. I build AI systems for UK service businesses every day. I run my own AI agent on a home server. And I can tell you: local AI models are not a gimmick. They're the future of how businesses will use AI. The only question is timing.
If you want to understand what local AI could mean for your specific business (and whether the timing is right for you), that's something we can explore in 20 minutes.
Find out what local AI could mean for your business
Fortnight & Co builds working AI systems for UK service businesses in 14 days. If we can't find a use case that saves your team 5+ hours per week, you don't pay.
Get your free automation auditFree - 20 minutes - No obligation - Custom report